當功能需求確定後,就要開始設計資料庫了。從商業邏輯轉換成資料庫設計時,可以利用資料庫正規化的方式(wiki:https://zh.wikipedia.org/zh-tw/%E6%95%B0%E6%8D%AE%E5%BA%93%E8%A7%84%E8%8C%83%E5%8C%96 )。
使用正規化時,最好要想一下使用的情境,到底該正規化到什麼地步才是最「合適」的,不過通常也會有另一個問題,這個系統到底需要多有「彈性」(大餅)?技術債怎麼留比較好?
開發時,大家常會討論這個欄位之後到底之後會不會變垃圾?現在的需求有,但非此階段任務,而使用者很容易變心,未來不確定,或者專案斷頭就沒了。總之各有利弊,就看誰能說服(X)作主(O)。世事難料,一直都只有「你看,我之前就講過了…」馬後砲最厲害。
不過這件事真的是待的位置不一樣,想法就會不一樣的很好例子。身為碼農工程師的內心OS就是:DB欄位現在不加,萬一開發時臨時又說要,這樣我不就白工了。要是下階段才加,有upgrade議題很麻煩,又是我要用,還要再改code一直判斷有值沒值,新資料/舊資料的差異。要是被拿去做FK之類的更慘,關聯join亂掉,SQL很難寫…等等的內心小劇場就出來了。所以說新鮮人菜鳥最可愛,因為還沒有經驗(跌過坑),小劇場跟本沒有劇本可以演,都很乖的照做,然後...看運氣XDb。
而當設計者或Leader時,就會開始拿各種學術理論,跟成本概念出來了,沒用到的就不要做了,架構要簡潔明瞭,好維護。時間已經很趕了,隕石案那能管那麼多,頭先過再說。而且一開始寫那麼複雜,開發期太長沒辦法早點demo,成果很難交代,而且user都是拖越久,想法越多越發散,更難搞。趕快出一版,給user用才會知道user的反應(每次都會有User真的看到功能後才說:「怎麼沒有xx?」SA:「當時你沒有講阿?」,順手拿出會議記錄。User:「通常是這樣子沒錯,但是還有oo例外,xyz...很少發生,但是每個月偶爾還是有一兩件...這個也要算阿,不然整個total就不對了...」)等等。
不過在當時的時空背景下,大家都是做當時自己覺得最有利的選擇,但經過時間演變後再來看,就很難講了。跟蓋房子/大樓社區(做系統)有點像,當初預售餅畫很大(開案需求),蓋(開發)得時候拖很久,理由很多:等建照下不來,缺工,缺料;蓋好後跟原本講得不一樣,點交(驗收)又出問題,施工品質不好會漏水,衛浴廚房偷工減料,磁磚沒貼好,牆壁沒抹平…;好不容易開始能住(上線)時,又有物業管理,管委會籌組議題(維運),游泳池要多花錢維護請救生員,又可能有公安乾脆不要開;再久一點,住戶(使用者)變多了,開始有奇怪/沒公德心/神經敏感,各式各樣的人出現,要是上了社會新聞(意外碰到了,真的是沒辦法);而後續社區風評(口碑,成功案例),也會影響後續的幾期推案(案子有沒有下一階段),時間(歷史)會演給你看,但還沒發生真的不知道。
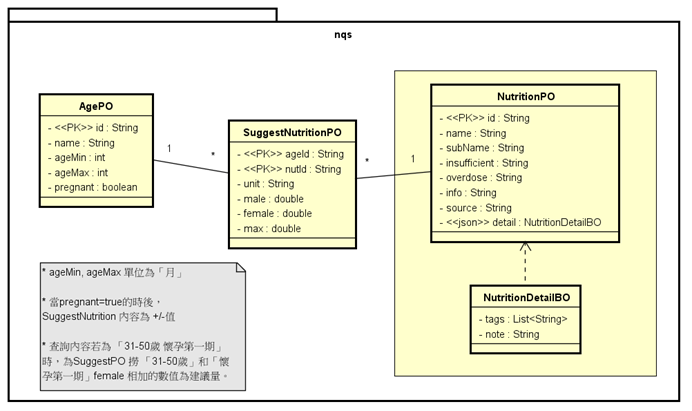
不過總之現在只是迷你功能,自己一條龍就不用管這麼多。因為使用JPA(原Java Persistence API,現在因package變更,更名為 Jakarta Persistence API)的架構(https://zh.wikipedia.org/zh-tw/Java%E6%8C%81%E4%B9%85%E5%8C%96API ),所以可以透過ORM (Object Relational Mapping,O/R mapping,https://zh.wikipedia.org/zh-tw/%E5%AF%B9%E8%B1%A1%E5%85%B3%E7%B3%BB%E6%98%A0%E5%B0%84 )的概念直接用Java PO 實作,所以設計PO也等於定好DB Schema,對CURD仔來說,是蠻方便的。
不過因為以前早期對hibernate(JPA是規格,hibernate是實作)的陰影,我習慣不在JPA上做會跨table的設定,ex: one-to-one,one-to-many,many-to-one...的設定,資料連結合併會在 service(組商業邏輯需要的資訊)或 controller(組UI/API需要的額外顯示資訊) 上組。所以在PO 上還是單一table操作為主,用Java 程式控制邏輯與資料庫資料表之間的關系。主要避免系統在不同階段增加/廢棄DB欄位,或統整外部系統資料時所造成的資料碰撞,或是不符合原設定規則的部份。因為JPA在啟動時,就會檢查資料合理性,不合理連server都起不起來!
而最近幾年,也習慣把一些描述內容集成一個物件(不會成為常用的資料過濾條件,optional的欄位,註記內容)直接塞成一個json string,存到DB內。類似 傳統SQL 跟 noSQL 概念合在一起用的方式。主要關聯,必要查詢條件項目作成DB欄位效率好,其json欄位,做為擴充,額外meta記錄的用途,減少正規化所需要的table。
大概就是傳統的主表,1對1子表,或1對多子表的項目(對多的內容沒有到上幾百筆以上的內容),若在應用中,不需要由子表查回主表時,這個子表內容擠成json進去其實沒有關系。若擔心AP跟DB 之間的IO 太大,就SQL下好指定的欄位,更新時部份更新,與不要 select * 就可以有效節省傳輸效率。
每次都會想到在保險業看到一次join幾十個table,怎麼想都沒辦法加快效率~囧rz。僅量控制 join 資料看能不能五個table內做完,超過時,寧願湊2~3道單一查詢匯整資訊,用程式Memory 額外處理可能還比較快。使用postgreSQL還有一個優點是,若真的需要操作json字串內容進行SQL查詢運用時,他有現成的json查詢函式可以使用,就是看是想吃AP的效能,還是吃DB的效能比較好。
附上這次的Class diagram初版,練習先紙上設計,再看後面寫程式會落差多少XD